PA2 Part 1 - Instruction Set Implementation & KLIB

If someone is reading this blog, please be aware that the writer DID NOT consider the experience of the other readers.
After all, the most important thing is about writing things down for better memorization.
Bit Operation Macros
- Bit operations are usually not very readable to human, so I decided to write down the explanations that I come up with here.
BITS && BITMASK
1 |
- These two macros are used to extract some of the bits from a binary number.
- Specifically, they are used to extract the ‘immediate’ from the instructions.
First we take a look at
BITMASK:This macro creates a bitmask of a specified number of bits.
For example,
BITMASK(3)would create a bitmask of 3 bits:0000...0111, which is the number7.The macro works by shifting the number
1to the left by bits positions and then subtracting1from the result:1->0000...1000(shift1to the left by 3 bits)0000...1000->0000...0111(subtract1from the result)
NB:
1ullstands for ‘unsigned long long integer’. The suffix ‘ull’ here is used to make the number164-bit
Then
BITS:This macro extracts bits from position
loto positionhifrom the valuex.It does it by performing several bit operations:
- First it shifts
xto the right bylopositions, which effectively removes the bits lower than the bit onloposition. - Second it masks
xwith the bitmask created by the macro explained above to wipe out all values higher than positionhiof the originalx.
- First it shifts
SEXT
1 |
SEXTstands for Sign Extension, which is the process of extending the sign bit of a binary number when moving it to a larger bit width.In the macro, the expression uses a bit field within a struct to define a signed integer of length
lenbits. The bit field ensures that the value ofxis treated as a signed integer of that specific length.The struct with the bit field automatically sign-extends the value when it is assigned to the
int64_tmember. The result is then cast back touint64_tto maintain the full precision of the extended value.
The second parameter len of SEXT macro means the number of bits to treat x as for sign extension, instead of the target length.
The reason why sign extension is needed is that, the offset(immediate) is a signed value and it’s length is less than 64 bits(well of course since the length of the whole instruction is merely 32 bits). If we directly store it in a 64-bit variable, the higher bits are filled with zeros by default.
Problem that sign extension resolves:
If we have a negative offset(immediate) presented as two’s complement, which means that it’s higher bits should all be
1.Now if we store it directly into a 64-bit variable, the higher bits are becoming
0s, thus making the variable a positive one.Example:
- Original 8-bit Signed Value: Let’s say you have the binary value
11111111(which is-1in two’s complement notation when interpreted as a 8-bit signed integer). - Direct Storage Without Sign Extension: If you store this 8-bit value directly into a 32-bit variable without sign extension, it would look like this:
00000000 00000000 00000000 11111111(which is255in decimal, a positive value).
- Original 8-bit Signed Value: Let’s say you have the binary value
Casts and Conventions: Ensuring Proper Sign Extension in C
In the implementation of instruction
mulh, I encountered a suttle issue deeply rooted in C’s type conversion conventions.RISC-V manual defines
mulhas follows:MUL performs an XLEN-bit×XLEN-bit multiplication of rs1 by rs2 and places the lower XLEN bits
in the destination register. MULH, MULHU, and MULHSU perform the same multiplication but return the upper XLEN bits of the full 2×XLEN-bit product, for signed×signed, unsigned×unsigned,
and signed rs1×unsigned rs2 multiplication, respectively.Essentially, it’s just an extended version
mul, designed for caculating larger numbers with lower precision.
My first implementation looks like this:
1
2
3
4INSTPAT(...);
INSTPAT("0000001 ????? ????? 001 ????? 01100 11", mulh, R,
R(rd) = ((int64_t)src1 * (int64_t)src2) >> 32);
INSTPAT(...);During the test of
mul-longlong.c, I used difftest to locate the problem is atpc = 0x800000a0, which is:1
800000a0:402fc17b3 mulh a5,s8,a5
The difftest showed a discrepancy:
1
[src/isa/riscv32/difftest/dut.c:23 isa_difftest_checkregs] a5 is different after executing instruction at pc = 0x800000a0, right = 0x19d29ab9, wrong = 0x7736200d, diff = 0x6ee4bab4
At first glance, the logic written in
inst.cseemed correct:- convert the value stored in the two registers to signed intergers.
- multiply them together, then shift right for 32 bits to get the upper 32 bits, and then store the result in the destination register.
It turns out that the problem rooted in the conversion process.
In C, when converting a smaller signed type to a larger signed type, for example, casting a 32-bit signed integer(
int32_t) to a 64-bit signed integer(int64_t), C correctly handles the sign extension, preserving the value after the conversion.The same thing happens when we convert an unsigned type to a same size signed type, C will do the sign extension automatically as well.
But, if we convert a smaller unsigned type, to a larger signed type, C does not automatically perform sign extension, which leads to the problem that I was facing with.
Consider this simple example program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main() {
// Max value for 32-bit unsigned integer
uint32_t u32 = 0xaeb1c2aa;
// Cast to a 64-bit signed integer
int64_t s64 = (int64_t)u32;
printf("u32: %u\n", u32);
printf("s32: %d\n", (int32_t)u32);
printf("directly converted s64: %ld\n", s64);
// Max value for 32-bit unsigned integer
uint32_t u32_2 = 0xaeb1c2aa;
// Cast to a 64-bit signed integer with sign extension
int64_t s64_2 = (int64_t)(int32_t)u32;
printf("expected s64: %ld\n", s64_2);
return 0;
}output:
1
2
3
4u32: 2930885290
s32: -1364082006
directly converted s64: 2930885290
expected s64: -1364082006From the example above we can see that: when directly convert a 32-bit unsigned integer to a 64-bit signed integer, C does not automatically perform sign extension.
That is the reason why my first implementation for instruction
mulhwas incorrect: it did not conduct sign conversion.
The solution is simple, first convert the value into a 32-bit signed int, then convert it into a 64-bit signed one:
1
2INSTPAT("0000001 ????? ????? 001 ????? 01100 11", mulh, R,
R(rd) = ((int64_t)(int32_t)src1 * (int64_t)(int32_t)src2) >> 32);
UPDATE
Though the notes shown above are correct, it’s more likely that the course wants us to use the
SEXTmacro for sign extension.The final version of
mulhlooks like this:1
2INSTPAT("0000001 ????? ????? 001 ????? 01100 11", mulh, R,
R(rd) = (SEXT(src1, 32) * SEXT(src2, 32)) >> 32);SEXTtreatssrc1as a 32-bit value(uint32_t), and sign-extends it to 64 bits.
Cross Compilation Env
When testing the implemented instructions, we would need to run tests in
am-kernels/tests/cpu-tests/tests/.The execution command is(take
dummy.cas example):1
make ARCH=$ISA-nemu ALL=dummy run
However, my machine(cpu) is of x86 architecture, which means that it can not compile source code to riscv32 executables directly.
We would need the following packages to perform the compilation:
1
sudo pacman -Sy riscv64-linux-gnu-gcc
Though still some errors may occur:
Possible Compilation Error
wordsize.h:
1
/usr/riscv64-linux-gnu/include/bits/wordsize.h:28:3: error: #error "rv32i-based targets are not supported"
- **solution**: modify `/usr/riscv64-linux-gnu/include/bits/wordsize.h` : 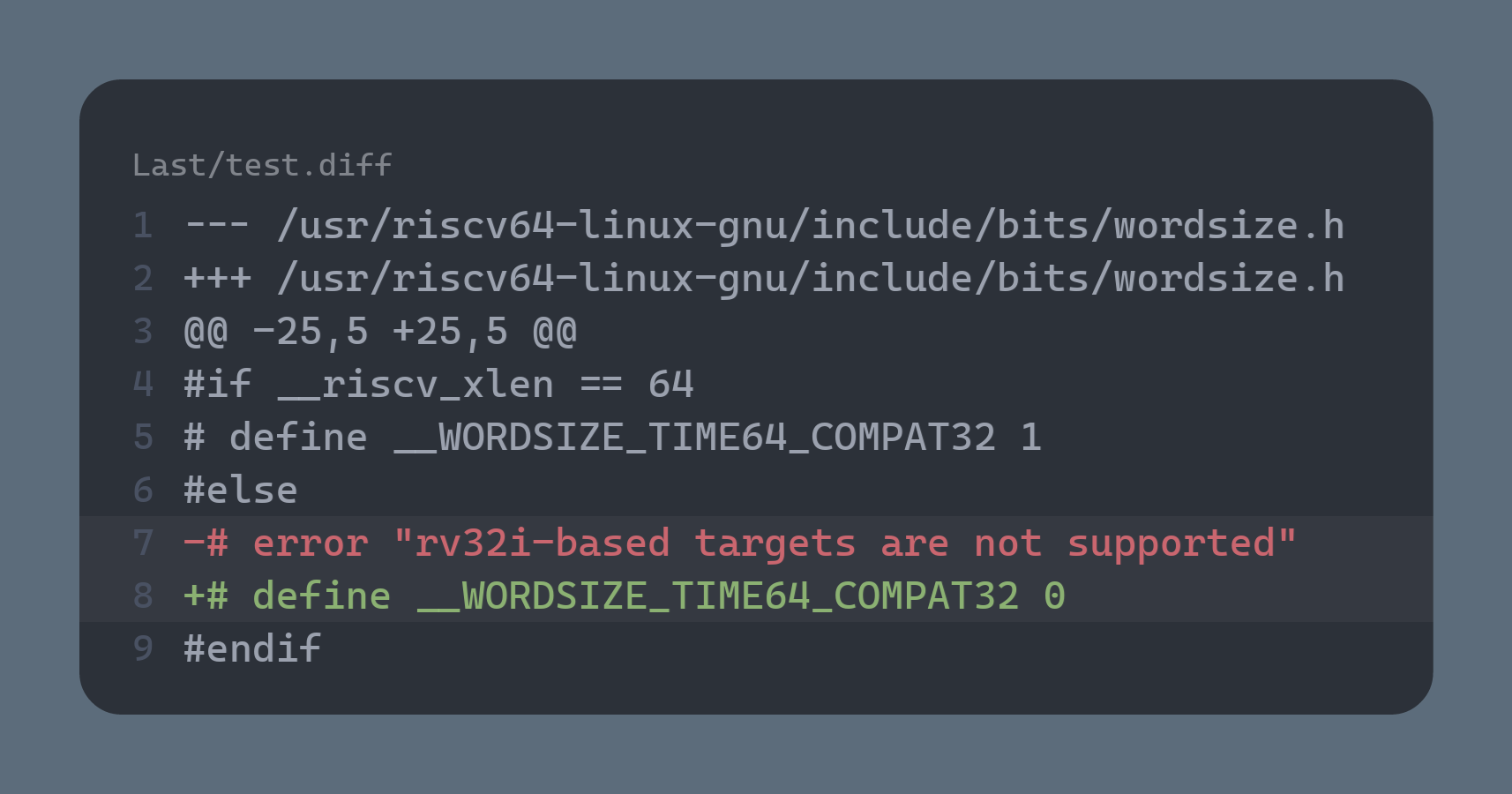stubs.h:
1
/usr/riscv64-linux-gnu/include/gnu/stubs.h:8:11: fatal error: gnu/stubs-ilp32.h: No such file or directory
- **solution**: modify `/usr/riscv64-linux-gnu/include/gnu/stubs.h` : 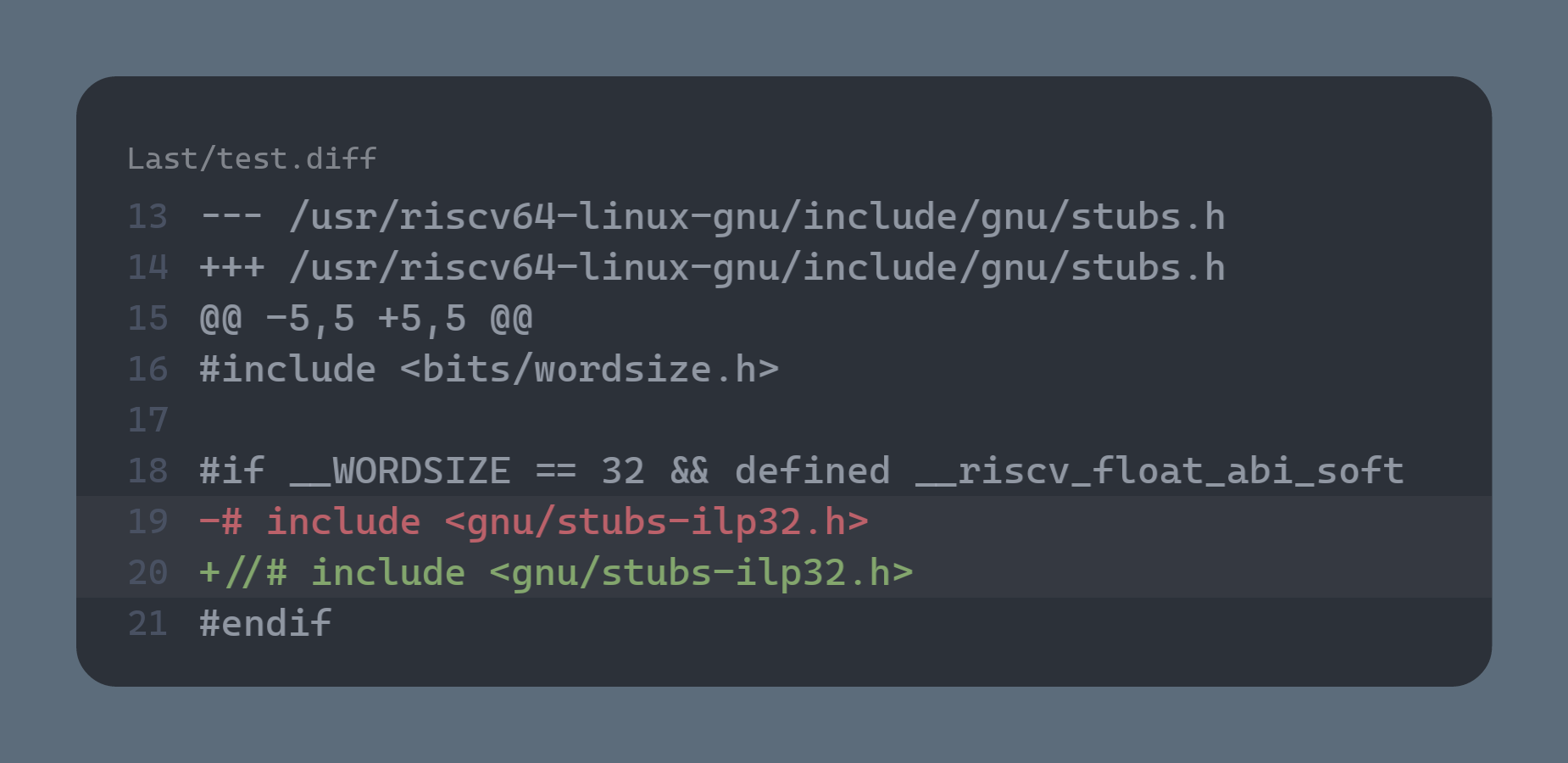
Weird int parameter of memset
When implementing our own lib utils, I encountered a little problem in
memset.The first version of my
memsetlooks like this:1
2
3
4
5
6
7
8
9void *memset(void *s, int c, size_t n) {
size_t *p = s;
for (size_t i = 0; i < n; i++) {
*p = c;
p++;
}
return s;
}The problem is that, the size of the memory which would be set by this function is of unit byte. However, here in my implemtation, the unit is int.
The correct version is:
1
2
3
4
5
6
7
8
9void *memset(void *s, int c, size_t n) {
unsigned char *p = s;
for (size_t i = 0; i < n; i++) {
*p = (unsigned char)c;
p++;
}
return s;
}We use
unsigned charto represent a byte in memory, as it’s size is exactly one byte.As for the reason of using
unsigned, it is because of that we want to eliminate the ambiguity of the various implemetation of signed char.
Parsing ELF
- Parsing ELF files is the most difficult part in
ftracedevelopment. I knew nothing about the elf file before reading the man page ofelffor two afternoons. - Here I recorded some of the most complicated part of the development for future review.
Wikipedia:
In computing, the Executable and Linkable Format(ELF, formerly named Extensible Linking Format) is a common standard file format for executable files, object code, shared libraries, and core dumps.
- We can use
readelf -ato extract the content stored in an ELF file. - Take a
hello.cas an example:
readelf
1 | readelf -a hello |
There’re a lot of information shown here. Let’s just focus on what we need: function symbols.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27Symbol table '.symtab' contains 25 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 0000000000000000 0 FILE LOCAL DEFAULT ABS
3: 0000000000003de0 0 OBJECT LOCAL DEFAULT 21 _DYNAMIC
4: 0000000000002010 0 NOTYPE LOCAL DEFAULT 17 __GNU_EH_FRAME_HDR
5: 0000000000003fe8 0 OBJECT LOCAL DEFAULT 23 _GLOBAL_OFFSET_TABLE_
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_mai[...]
7: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
8: 0000000000004008 0 NOTYPE WEAK DEFAULT 24 data_start
9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@GLIBC_2.2.5
10: 0000000000004018 0 NOTYPE GLOBAL DEFAULT 24 _edata
11: 0000000000001170 0 FUNC GLOBAL HIDDEN 15 _fini
12: 0000000000001139 22 FUNC GLOBAL DEFAULT 14 hello
13: 0000000000004008 0 NOTYPE GLOBAL DEFAULT 24 __data_start
14: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
15: 0000000000004010 0 OBJECT GLOBAL HIDDEN 24 __dso_handle
16: 0000000000002000 4 OBJECT GLOBAL DEFAULT 16 _IO_stdin_used
17: 0000000000004020 0 NOTYPE GLOBAL DEFAULT 25 _end
18: 0000000000001040 38 FUNC GLOBAL DEFAULT 14 _start
19: 0000000000004018 0 NOTYPE GLOBAL DEFAULT 25 __bss_start
20: 000000000000114f 32 FUNC GLOBAL DEFAULT 14 main
21: 0000000000004018 0 OBJECT GLOBAL HIDDEN 24 __TMC_END__
22: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMC[...]
23: 0000000000000000 0 FUNC WEAK DEFAULT UND __cxa_finalize@G[...]
24: 0000000000001000 0 FUNC GLOBAL HIDDEN 12 _initFrom the above symbol table we can see that, among all of the symbols, those with type
FUNCshould be the ones that we want for ftrace.However, it’s not that simple.
- It’s not easy to locate and read the symbol table from an ELF file since it’s in binary.
- The
NAMEin the symbol table is actually an offset used to search from string table.
To resolve these two issues, we will need to take a look at the structure of a common ELF file.
ELF File Structure
Basically, a common ELF file contains an ELF header, which includes information about itself, such as:
e_ident: a magic number identifying the file as an ELF filee_shoff: section header’s offsete_shnum: count of section headerse_shstrndx: index of the names’ section in the table
Those variables are the guides for us to extract useful content from the ELF file.
Other parts of ELF file, such as section header table, string table and section name string table, can be found using these offsets extracted from ELF header.
But how exactly should we read them from an ELF file? The answer is, with the help of
<elf.h>.
<elf.h>
man 5 elf :
The header file <elf.h> defines the format of ELF executable binary files. Amongst these files are normal executable files, relocatable object files, core files, and shared objects.
An executable file using the ELF file format cosists of an ELF header, followed by a program header table or a section header table, or both. The ELF header is always at offset zero of the file. The program header table and the section header table’s offset in the file are defined in the ELF header. The two tables describe the rest of the particularities of the file.
This header file defines a lot of types(structs) to help users read from the binary ELF files.
For example, a struct
Elf32_Ehdrof ELF header:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct {
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx;4 /* Section header string table index */
} Elf32_Ehdr;We can use it to define a variable and store the content read from the file to it:
1
2
3// read the whole ELF file
ElfW(Ehdr) ELF_header;
fread(&ELF_header, sizeof(ELF_header), 1, file);BTW, there’s a macro
ElfWused here:1
2
3
4
5I have to say, that, macro is kinda useful. While I disliked it when first encountered it.
We could then use the
e_shofffrom the ELF header to locate the position of section headers:1
2
3
4
5
6
7
8// read section headers
size_t sh_entry_size = sizeof(ElfW(Shdr));
ElfW(Shdr) *shdrs = malloc(ELF_header.e_shnum * sh_entry_size);
Assert(shdrs, ANSI_FMT("Failed to allocate memory for section headers\n",
ANSI_FG_RED));
fseek(file, ELF_header.e_shoff, SEEK_SET);
fread(shdrs, sh_entry_size, ELF_header.e_shnum, file);And so on.
Missing Symbols in ELF
Sometimes
gccautomatically inlines functions written in the source file.In this case, they are not shown in the symbol table as there’s no such symbol after pre-compilation.
We can use an attribute to stop
gccfrom inlining these functions:1
int is_prime(int n) __attribute__((noinline));
use-after-free Error
1 | FuncSym func = { |
I ran into this problem as the code shown above. This is the first time I encounter with a use-after-free error, so it took me a while to figure out what’s happening.
The tricky part of this bug is that, there’re no errors reported by compiler or the program itself, it just caused the output info from the function table to be random characters.
Solution: use
strdupto duplicate a string from thestring_table.1
2
3
4
5FuncSym func = {
.name = strdup(&string_table[symbol_table[i].st_name]),
.value = symbol_table[i].st_value,
.size = symbol_table[i].st_size,
};
Implementing <string.h>
- Recording some interesting implementation in
<string.h>here.
strcmp
1 | int strcmp(const char *s1, const char *s2) { |
- Iterating through the two strings and returns the difference between the first unmatched character.
memset
1 | void *memset(void *s, int c, size_t n) { |
- Use
unsigned charas a byte in memory.
Implementing sprintf
- For the moment we would only need to implement two specifiers:
%dand%s.
I was first very hesitate to begin with this implementation cuz I thought it was going to be difficult. But as soon as I dived into it, it’s actually not that hard as I anticipated.
My first idea was to maintain a dynamic array with
mallocandreallocto store the final buffer for output. But I soon found that I would have to implementmallocandreallocas well this way…So I turned to a fiexed length buffer instead.
- The idea is simple:
- Read the
fmtargument character by character, put that character into buffer if it is not%, which is the start of a specifier. - When encountering a specifier, use
va_argto pop the next arguement with proper type, convert it into a character or a string, and then take it into the buffer. - When the parsing of
fmtis done, usestrcpywe’ve implemented before to copy the buffer intoout.
- Read the
DiffTest
device-tree-compiler on ArchLinux
device-tree-compileris a package required for conducting difftest onspike.This pacakge is named
dtcin Arch Linux official repo.1
sudo pacman -Sy dtc
How Does the VM Intercepts Memory Reading Action?
Why could we directly read memory-mapped address in a way of pointer dereferencing in AM?
1
static inline uint8_t inb(uintptr_t addr) { return *(volatile uint8_t *)addr; }
Cuz these memory reading codes will be compiled to assembly, which is basically riscv32 instructions containing the address to be read. When nemu proceeds through these instructions, it will parse it and invoke
paddr_readfunction(Mrmacro, which invokevaddr_read->paddr_read), and that’s where the callback function binds to a mapped memory area reading is invoked.
Why volatile ?
- In short,
volatileis used to prevent the compiler from optimizing away memory access, especially in this case, which is dealing with memory-mapped IO (MMIO). - Without
volatile, the compiler might optimize away repeated memory reads or writes, assuming the memory value won’t change unexpectedly. This assumption is valid for normal variables, but memory-mapped registers and hardware I/O can change asynchronously. - For example, reading from an MMIO address might trigger a hardware event or return different values based on the state of the peripheral device. Without
volatile, the compiler might cache the value read from memory in a register and never actually perform the memory read again.
Link to Part2
- Title: PA2 Part 1 - Instruction Set Implementation & KLIB
- Author: Last
- Created at : 2024-10-03 01:37:00
- Link: https://blog.imlast.top/2024/10/02/nju-pa-2/
- License: This work is licensed under CC BY-NC-SA 4.0.