阅读 MQTTX 项目:CLI 【1】

前言
本系列博文用于记录笔者阅读 MQTTX (主分支) 时产生的理解和疑问,用于与导师进行沟通和日后翻阅。
采用文章的方式是由于该方式的信息传递效率相较于即时通讯软件要高得多,能够最大程度的节约导师的时间。
此外,由于我的工作是添加
AVRO编码支持,所以阅读代码的起点是 CLI 部分中的编解码部分。
数据格式转换函数耦合程度较高
在阅读项目 CLI 部分代码时,我注意到用于转换 payload 的函数看起来相对复杂——编解码的工作往往同一个函数中执行。换句话说,这些函数承担了不止一种职责,意味着他们违反了单一功能原则。
相关代码如下所示:
convertJSON:1
2
3
4
5
6
7
8
9const convertJSON = (value: Buffer | string, action: Action) => {
try {
return action === "decode"
? jsonStringify(jsonParse(value.toString()), null, 2)
: Buffer.from(jsonStringify(jsonParse(value.toString())));
} catch (err) {
return handleError(err, value, action);
}
};将
encode和decode两种功能放置于同一个函数中是否有些不妥?这导致了一个额外的(不必要)的参数(及其类型)action。同时导致了value参数类型的不唯一 (Buffer | string),进一步导致了函数操作的复杂化(需要jsonStringify(jsonParse(...))),降低可读性以及可维护性。…
convertPayload:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28const convertPayload = (
payload: Buffer | string,
format?: FormatType,
action: Action = "decode"
) => {
const actions = {
encode: {
base64: () => Buffer.from(payload.toString(), "base64"),
json: () => convertJSON(payload, "encode"),
hex: () => Buffer.from(payload.toString().replace(/\s+/g, ""), "hex"),
cbor: () => convertCBOR(payload, "encode"),
binary: () => payload,
default: () => Buffer.from(payload.toString(), "utf-8")
},
decode: {
base64: () => payload.toString("base64"),
json: () => convertJSON(payload, "decode"),
hex: () => payload.toString("hex").replace(/(.{4})/g, "$1 "),
cbor: () => convertCBOR(payload, "decode"),
binary: () => payload,
default: () => payload.toString("utf-8")
}
};
const actionSet = actions[action];
const runAction = actionSet[format || "default"];
return runAction ? runAction() : payload;
};相似的问题,不过除了两种截然相反的功能耦合在同一个函数中以外,所有的编码格式都使用这一个函数进行编解码……
奇怪的 pipeline
processReceivedMessage:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28const processReceivedMessage = (
payload: Buffer,
protobufPath?: string,
protobufMessageName?: string,
format?: FormatType
): string | Buffer => {
let message: string | Buffer = payload;
/*
* Pipeline for processing incoming messages, following two potential steps:
* 1. Protobuf Deserialization --> Utilized if both protobuf path and message name are defined, otherwise message passes as is.
* 2. Format Conversion --> Engaged if a format is defined, converting the message accordingly; if not defined, message passes unchanged.
*/
const pipeline = [
(msg: Buffer) =>
protobufPath && protobufMessageName
? deserializeBufferToProtobuf(msg, protobufPath, protobufMessageName, format)
: msg,
(msg: Buffer) => (format ? convertPayload(msg, format, "decode") : msg)
];
message = pipeline.reduce((msg, transformer) => transformer(msg), message);
if (Buffer.isBuffer(message) && format !== "binary") {
message = message.toString("utf-8");
}
return message;
};- 总共只有两个预处理步骤的情况,真的有必要牺牲可读性,使用
pipeline这种写法么? - 此外,
deserializeBufferToProtobuf的返回值类型是any,而pipeline中的第二个步骤函数接受的参数类型为Buffer。这是否是一个潜在的问题?
- 总共只有两个预处理步骤的情况,真的有必要牺牲可读性,使用
关于 Schema(avro) 的定义方式
注意到:用户可以在 ‘Script’ 中 ‘Schema’ 区域定义 serialize 数据所使用的 Schema。请问可以拓展这个部分的功能以达到定义 Avro Schema 的功能吗?
注意到该页面上有一个下拉菜单,内部只有一个 ‘Protobuf’ 的选项。是否可以在其中添加 ‘Avro’ 的选项,并在此页面定义相关 Schema?
如图:
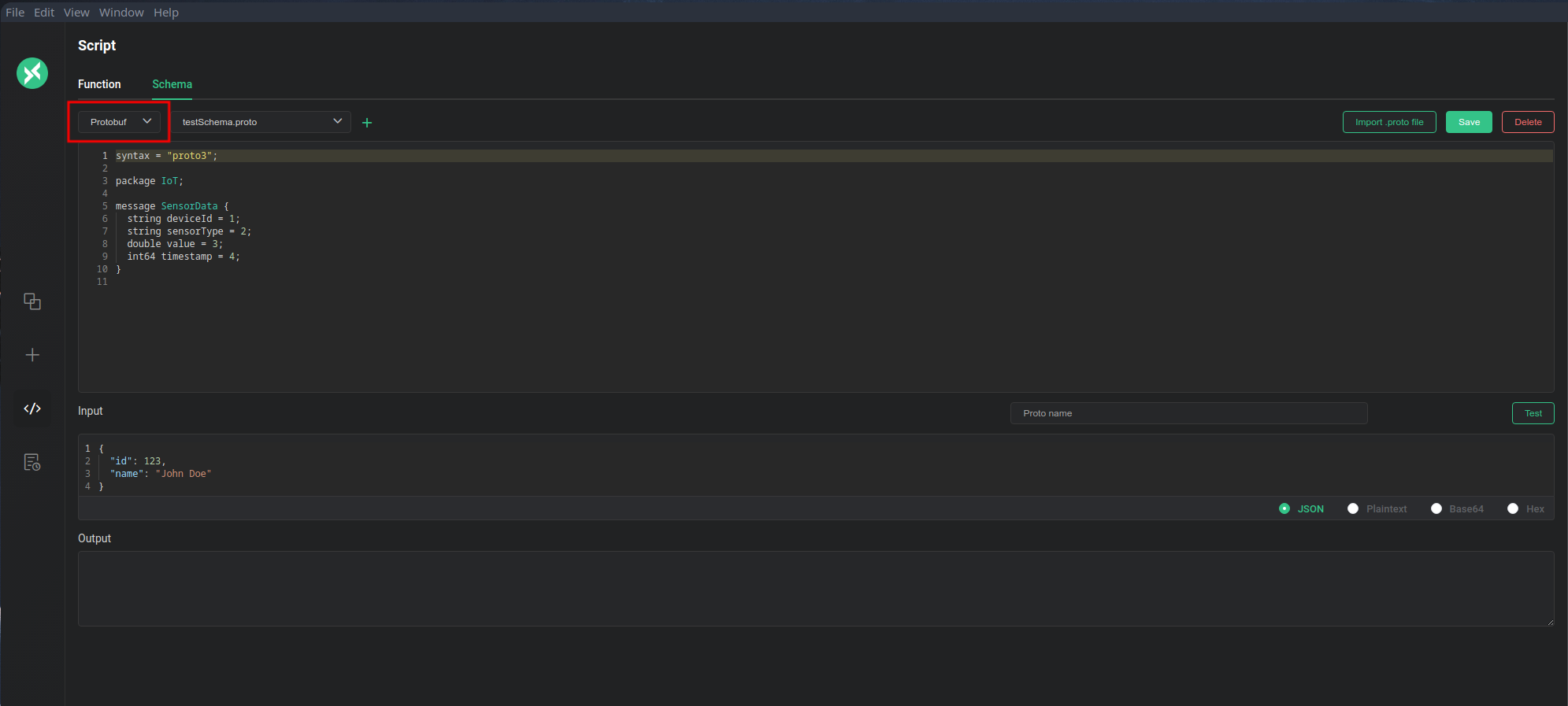
如若采用此种定义方案,在 CLI 部分的代码中,读取 Schema 并采取编码操作的代码应处于
processPublishMessage中: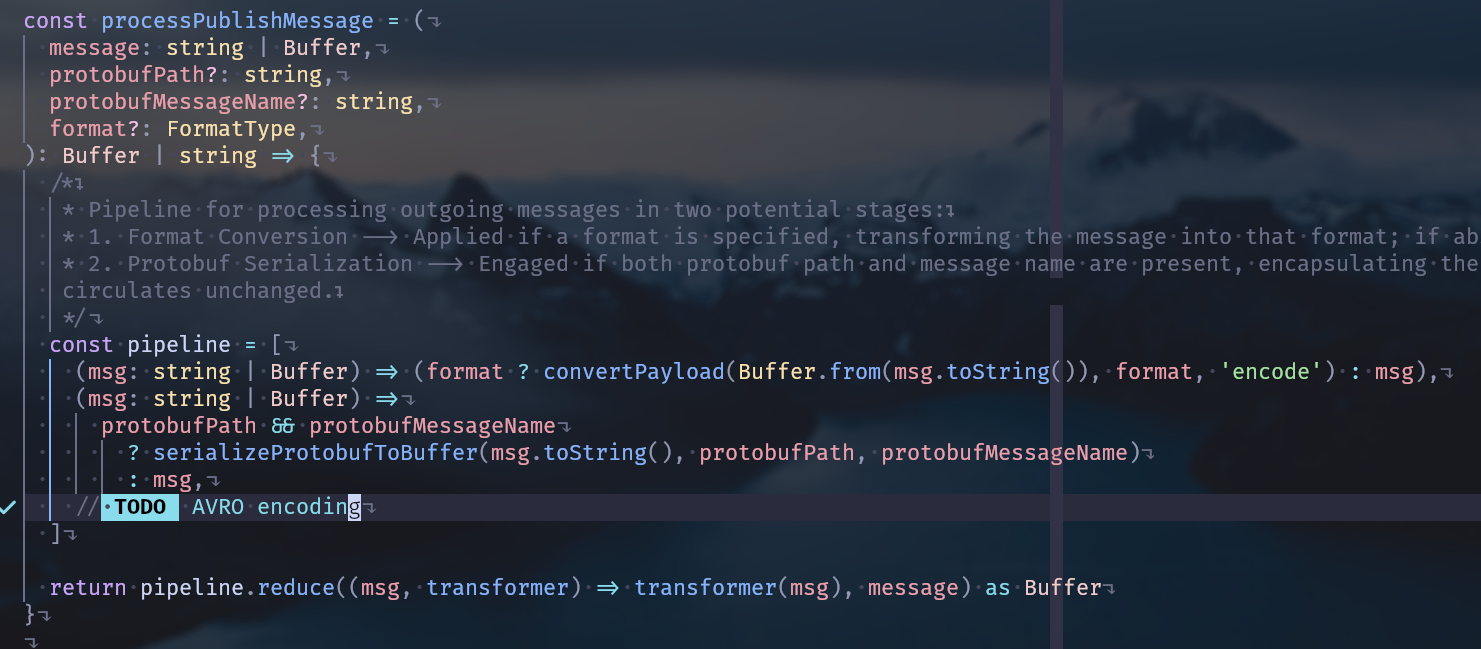
(需要定义一个新的模块用于处理 avro 相关的编解码,以及 Schema 存取)同时,需要在命令行参数中添加一项来指定 AVRO Schema 所在的文件,让程序读取 Schema 用于编码。
然而,程序通过
format参数来确认所需要发送/接受的数据使用的编码格式,意味着通常来说,AVRO 的编解码应当是要走convertPayload这个函数的。但是处理 avro 编解码的操作在逻辑上更接近serializeProtobufToBuffer函数。因此我对于该在何处处理 avro 编解码感到有些犹豫。
关于 Schema(avro) 的同步方案
在申请书中提到过,Avro 消息的 Schema 传输有两种计划方式:
- 在每条消息中包含 Schema
- 仅在每个 topic 的第一条消息中包含 Schema
- 手动定义 Schema (所有消息中均不包含 Schema)
此前我考虑到 MQTT 协议的目的是在“资源受限的设备和低带宽、高延迟或不可靠的网络中提供可靠的、轻量级的消息传输协议”,认为第一种方式并不符合 MQTT 协议的设计原则。
但是现在我发现,MQTTX 作为一款“集成多功能的 MQTT 测试工具箱”,似乎并不需要考虑许多实际场景中的因素。
此外,关于所接受到的 Schema 改如何存储呢?是存在程序运行的内存之中,还是保存到本地呢?
说老实话,现在我对于 Schema 的分发和存储方式有些迷茫,还望提供一些建议。
End
- Title: 阅读 MQTTX 项目:CLI 【1】
- Author: Last
- Created at : 2024-07-16 04:27:27
- Link: https://blog.imlast.top/2024/07/15/reading-mqttx-1/
- License: This work is licensed under CC BY-NC-SA 4.0.